いまさら聞けない!C言語のポインタと配列の違い
配列とポインタは「似ている」のではなく
似た振る舞いをする瞬間があるだけです
この記事では
int a[5]とint *pの違いを本質から整理したい- sizeofや関数引数で混乱したことがある
- 配列はポインタの別名だと思っている
そんなモヤっとを、構造から整えていきます
まず、いきなり結論を言います
配列は「実体」
ポインタは「参照」
ここがすべてです
なぜ同じに見えるのか
int a[5] = {1,2,3,4,5};
int *p = a;どちらも
a[0]
p[0]と書けます
だから混乱します
しかし中身はまったく違います
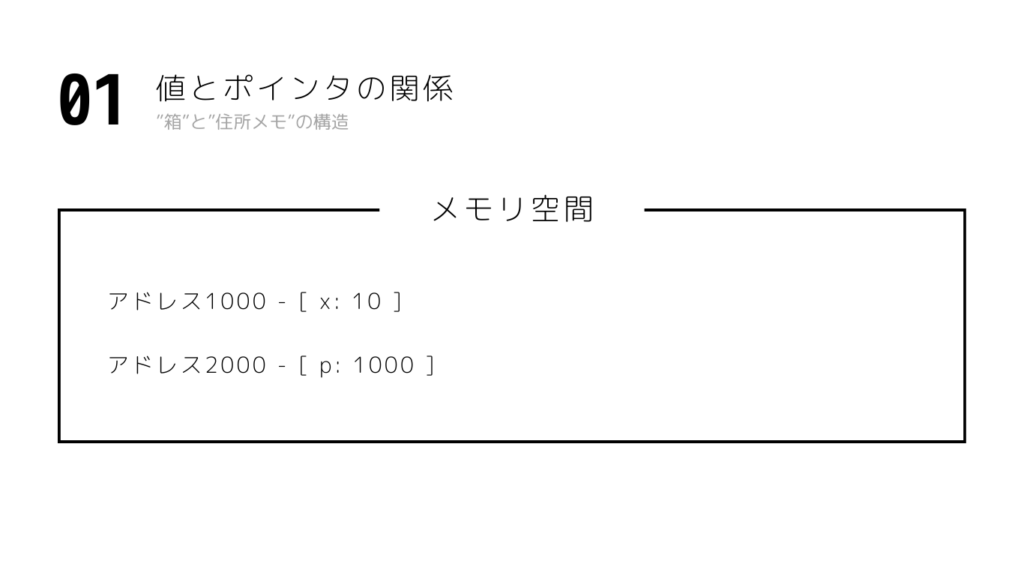
配列の正体

a はこの領域そのものです
a は
「先頭アドレスを表す式」に変換されることはありますが、実体を持つ変数です
重要なのはここです
配列はメモリを“所有”しています
ポインタの正体

p の中身は「1000」という数値
つまりアドレスです
p 自体は、配列を持っていません
決定的な違い①:sizeof
int a[5];
int *p = a;
sizeof(a); // ?
sizeof(p); // ?64bit環境なら
- sizeof(a) → 20
- sizeof(p) → 8
になります
なぜか
- a は 5個の int を持つ実体
- p は 1つのアドレスを持つ変数
ここを説明できるかが理解の分かれ目です
決定的な違い②:代入できるか
int a[5];
int b[5];
a = b; // コンパイルエラー配列は代入できません
なぜなら
配列は「固定された実体」だからです
一方
int *p;
int *q;
p = q; // OKポインタはアドレスを書き換えられます
決定的な違い③:関数引数での挙動
void func(int arr[5]);これは実際には
void func(int *arr);と同じです
ここで
「ほら、配列はポインタじゃん」
と思いがちですが、違います
配列は
関数に渡された瞬間
ポインタに変換される
だけです
これを「配列の退化」と呼びます
関数呼び出し時の変換

実体は外側
関数内ではアドレスのみ
よくある誤解
配列名はポインタ変数である
これは誤りです
配列名は
- 左辺値になれない
- アドレスを書き換えられない
つまり
ポインタっぽい振る舞いをする式
であって
ポインタ変数ではありません
配列ポインタとポインタ配列
ここも混乱ポイントです
int (*p)[5]; // 配列へのポインタ
int *p[5]; // ポインタの配列まったく違います
前者は
5要素配列を指すポインタ
後者は
ポインタを5個持つ配列
宣言は右から読む
これを意識すると整理できます
実務視点での違い
設計の観点では
配列は
- サイズが固定
- 自動領域に置かれることが多い
- 所有権が明確
ポインタは
- 可変サイズ
- 動的確保
- 所有権設計が必要
配列は「箱」
ポインタは「接続」
役割が違います
まとめ
配列とポインタは似ています
しかし本質はまったく違います
配列は
- 実体
- 連続領域
- 固定サイズ
ポインタは
- アドレスを持つ変数
- 書き換え可能
- 実体を持たない
この違いを
sizeof・代入可否・関数引数
この3点で説明できれば
理解はかなり深い位置にあります
C言語ポインタを“理解した人”になるための再整理
C言語のポインタは「分かったつもり」から「使いこなせる」に変わる瞬間があって、そこを越えるとコードの見え方が一気に変わります
この記事は、
- ポインタの基本文法は理解している
- ダブルポインタや関数ポインタで一瞬止まる
- メモリを意識した設計をできるようになりたい
- 「なんとなく」から「意図して」使えるようになりたい
そんな方に向けた内容です
「アドレスを持つ変数」という説明で止まっていませんか
「*と&の記号操作」に意識が向いて、本質がぼやけていませんか
ここでは、ポインタを 概念 → メモリ構造 → 設計視点 の順で整理していきます
ポインタは「値」ではなく「関係性」
多くの人がポインタを
アドレスを格納する変数
と理解します
もちろん正しいです
ただし、それだけでは浅いです
本質は
あるデータと別の場所を“つなぐ仕組み”
です
int x = 10;
int *p = &x;ここで重要なのは
- p が x を指していること
- p を通して x にアクセスできること
- x と p は別物であること
ポインタは「値のコピー」ではなく「実体への参照経路」です
なぜポインタが必要なのか
ここが曖昧なままだと応用で詰まります
1. コピーを防ぐ
大きな構造体を値渡しするとコピーが発生します
void update(struct Data d); // コピー
void update(struct Data *d); // 参照設計の段階で「コピーさせるか」「実体を触らせるか」を選択できるのがポインタです
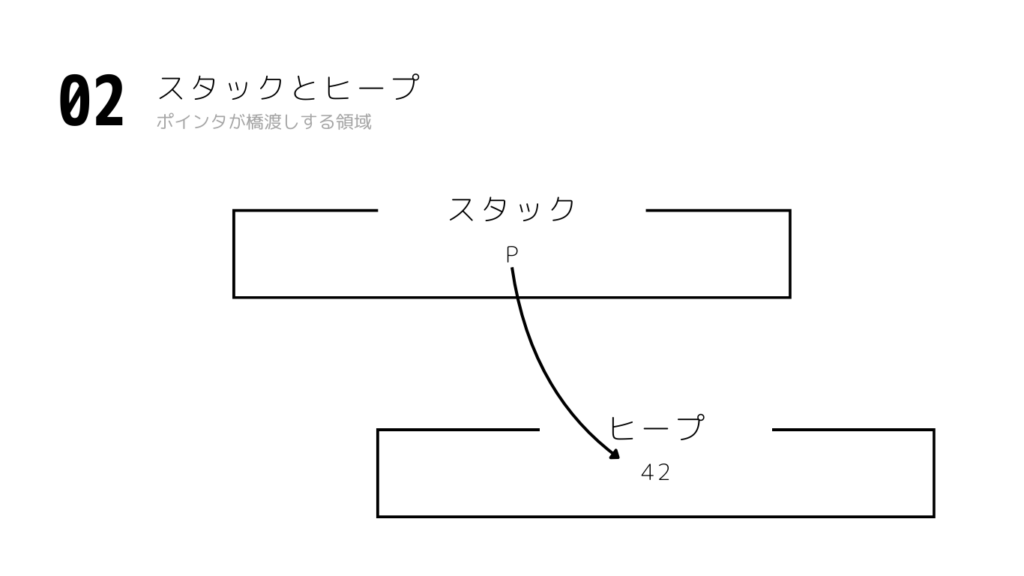
2. 動的メモリ管理
int *p = malloc(sizeof(int));スタックではなくヒープを扱う
これは実務で必須です
3. データ構造の実装
リスト、ツリー、グラフ
すべてポインタ前提です
ダブルポインタで止まる理由
int **pp;これは
実体を指すポインタを指すポインタ
言葉にすると混乱します
整理すると
x ← p ← ppx : 10
p : &x
pp : &pダブルポインタは
- 関数内でポインタを書き換えたいとき
- 二次元配列を扱うとき
- 可変構造を生成するとき
で使われます
現役プログラマ視点でのポインタ
実務で大事なのは
「何を指させるか」より
「どこまで責任を持つか」です
- 誰がメモリを確保するのか
- 誰が free するのか
- NULL を許す設計か
ポインタは便利ですが、責任境界を曖昧にすると事故になります
設計段階で
- 所有権
- ライフタイム
- 変更可否
を明確にする
これがポインタ理解の“深い段階”です
よくある混乱ポイント
1. 配列とポインタの違い
int a[5];
int *p;配列は実体
ポインタは参照
sizeof(a) と sizeof(p) が違う理由を説明できるか
ここが理解の指標です
const の位置
const int *p;
int *const p;どちらが何を固定しているか
これは
- データを守るのか
- ポインタを守るのか
という設計の違いです
ポインタ理解が進むと何が変わるか
- C++の参照の意味が明確になる
- Rustの所有権モデルが理解しやすくなる
- メモリリークを感覚で察知できる
- パフォーマンス設計ができるようになる
C言語のポインタは、低レイヤ理解の入口です
まとめ
ポインタは
- アドレスを持つ変数
ではなく - 実体との関係を表現する仕組み
です
記号操作ではなく
- メモリ空間をイメージできるか
- 所有権を設計できるか
- ライフタイムを意識できるか
ここまで到達すると
ポインタは怖いものではなくなります
SwiftでのMapと連想配列応用|配列・Dictionaryの便利メソッド活用
この記事でわかること
- SwiftでのMap操作の基本と応用
- 配列やDictionaryに対する
map、filter、reduceの使い方 - キーと値を使った変換やデータ整理テクニック
- 実用例で学ぶデータ処理の効率化
SwiftのMapとは
Swiftではmapというメソッドを使うことで、配列や辞書の要素を変換することができます
- 配列に対しては「各要素を変換して新しい配列を作る」
- Dictionaryに対しては「値を変換して新しいDictionaryを作る」
map以外にも、filterやreduceを組み合わせると、データ処理がもっと柔軟になります
配列でのMap応用
基本
let numbers = [1, 2, 3, 4, 5]
let squaredNumbers = numbers.map { $0 * $0 } // [1, 4, 9, 16, 25]Filterと組み合わせ
let evenSquares = numbers.filter { $0 % 2 == 0 }.map { $0 * $0 } // [4, 16]Reduceで合計を計算
let sum = numbers.reduce(0, +) // 15DictionaryでのMap応用
値だけ変換
let capitals = ["日本": "東京", "フランス": "パリ"]
let upperCapitals = capitals.mapValues { $0.uppercased() }
// ["日本": "東京", "フランス": "PARIS"]条件付きで抽出して変換
let filteredCapitals = capitals
.filter { $0.key.hasPrefix("日") }
.mapValues { $0 + "市" }
// ["日本": "東京市"]実践的なデータ整理テクニック
文字列配列をDictionaryに変換
let fruits = ["りんご", "みかん", "バナナ"]
let fruitLengths = Dictionary(uniqueKeysWithValues: fruits.map { ($0, $0.count) })
// ["りんご": 3, "みかん": 3, "バナナ": 3]Dictionaryをソート
let sortedCapitals = capitals.sorted { $0.key < $1.key }
for (country, capital) in sortedCapitals {
print("\(country): \(capital)")
}Dictionaryの値の集計
let sales = ["A": 100, "B": 200, "C": 150]
let totalSales = sales.values.reduce(0, +) // 450まとめ
SwiftのmapやmapValuesを使うと、配列やDictionaryの要素を簡単に変換できるfilterやreduceと組み合わせると、条件抽出や集計などの高度なデータ処理も効率的に行える
実務でよくあるデータ整理・変換の多くは、この組み合わせでシンプルに書ける
慣れてくると、「一度に変換・集計・フィルタリング」がスマートにできるので、コードがすごく読みやすくなる
SwiftでDictionaryを使いこなす方法|キーと値で管理する便利データ構造
この記事でわかること
- SwiftのDictionaryの基本概念
- Dictionaryの作成方法と要素の追加・削除・更新
- キーによる検索や存在チェック
- 配列やSetとの違い、便利なメソッドの活用
SwiftのDictionaryとは
Dictionaryは「キーと値」のペアでデータを管理するデータ構造です
キー(Key)はユニークで、値(Value)は任意の型を持つことができます
簡単に言うと、「名前で値を管理する箱」のようなイメージです
| 特徴 | 配列(Array) | Set | Dictionary |
|---|---|---|---|
| 順序 | 順序あり | 順序なし | 順序なし(Swift5以降は挿入順を保持) |
| 重複 | 値は可能 | 不可 | キーは不可、値は可能 |
| 検索 | インデックス | O(1) | キーで高速アクセス可能 |
Dictionaryの基本操作
作成
var capitals: [String: String] = [
"日本": "東京",
"アメリカ": "ワシントンD.C.",
"フランス": "パリ"
]要素の追加・更新
capitals["イギリス"] = "ロンドン" // 新しい要素を追加
capitals["日本"] = "京都" // 既存の値を更新要素の削除
capitals.removeValue(forKey: "アメリカ")値の取得
if let capital = capitals["フランス"] {
print("フランスの首都は \(capital)")
}Dictionaryの便利な使い方
キーの存在チェック
if capitals.keys.contains("日本") {
print("日本の首都が登録されている")
}ループでの操作
for (country, capital) in capitals {
print("\(country) の首都は \(capital)")
}値だけ、キーだけを取り出す
let allCountries = Array(capitals.keys)
let allCapitals = Array(capitals.values)まとめ
Dictionaryは「キーで値を管理する便利な箱」
検索や更新が高速で、データを整理して扱うのに最適
配列やSetと使い分けることで、Swiftでのデータ処理がより効率的になる
慣れてきたらmapValuesやfilterなどを活用して、さらにスマートに操作できる
SwiftでSetを使いこなす方法|重複なしデータの管理と基本操作
この記事でわかること
- SwiftのSetの特徴と基本概念
- Setの作成方法と要素の追加・削除
- Setを使った重複チェックや集合演算
- 配列との違い、便利なメソッドの活用
SwiftのSetとは
Setは「重複しない値の集まり」を扱うデータ構造です
順序は保証されず、同じ値を複数持つことはできません
配列との違いをまとめるとこんな感じ
| 特徴 | 配列(Array) | 集合(Set) |
|---|---|---|
| 順序 | 順序あり | 順序なし |
| 重複 | 可能 | 不可 |
| 検索速度 | O(n) | O(1)(平均) |
Setの基本操作
作成
var fruits: Set<String> = ["りんご", "みかん", "バナナ"]要素の追加
fruits.insert("ぶどう")要素の削除
fruits.remove("みかん")要素の確認
if fruits.contains("バナナ") {
print("バナナが入っているよ")
}Setの便利な使い方
集合演算
Setは集合演算が得意で、複数のSetを組み合わせることができます
let setA: Set = [1, 2, 3, 4]
let setB: Set = [3, 4, 5, 6]
let unionSet = setA.union(setB) // 和集合
let intersectionSet = setA.intersection(setB) // 積集合
let differenceSet = setA.subtracting(setB) // 差集合
重複の排除
配列の重複を簡単に削除したいときは、Setに変換するだけ
let numbers = [1, 2, 2, 3, 3, 3]
let uniqueNumbers = Set(numbers)まとめ
Setは「順序を気にせず、重複を許さないデータ管理」ができる
集合演算や重複チェックを簡単に行えるので、配列より効率的な場合も多い
配列との使い分けを理解しておくと、Swiftのデータ処理がもっとスムーズになる
Swiftで配列を使いこなす方法|基本操作から応用テクニックまで
この記事でわかること
- Swiftで配列(Array)を作成する方法
- 配列へのデータの追加・削除・変更の基本操作
- 配列の検索や並び替え、フィルタリングのテクニック
- 配列のイテレーションや便利なメソッドの活用方法
Swiftの配列とは
Swiftの配列(Array)は、同じ型の値を順序付きで格納できるデータ構造です
Arrayは非常に柔軟で、要素の追加・削除・並び替え・検索などが簡単に行えます
例えば整数のリスト、文字列のリスト、オブジェクトのリストなどを扱うことが可能です
var numbers: [Int] = [1, 2, 3, 4, 5]
var fruits: [String] = ["りんご", "みかん", "バナナ"]配列の基本操作
要素の追加
配列の末尾に要素を追加するにはappendを使います
fruits.append("ぶどう")特定の位置に追加したい場合はinsert(_:at:)を使います
fruits.insert("メロン", at: 1)要素の削除
末尾の要素を削除する場合はremoveLast()を使います
fruits.removeLast()指定した位置の要素を削除する場合はremove(at:)を使います
要素の変更
インデックスを指定して要素を変更できます
fruits[0] = "スイカ"配列の便利な操作
ループでの操作
配列の要素を順に取り出すにはfor-inを使います
for fruit in fruits {
print(fruit)
}検索
配列の中に特定の値があるか調べるにはcontainsを使います
if fruits.contains("バナナ") {
print("バナナが入っているよ")
}並び替え
配列を昇順や降順に並べ替えるにはsortやsortedを使います
numbers.sort() // numbersが昇順に並び替えられる
let reversedNumbers = numbers.sorted(by: >) // 降順で新しい配列を作るフィルタリング
条件に合う要素だけを取り出すにはfilterを使います
let evenNumbers = numbers.filter { $0 % 2 == 0 }まとめ
Swiftの配列は非常に使いやすく、データの追加・削除・検索・並び替え・フィルタリングなど、多彩な操作が可能
基本を押さえておくだけでも多くのプログラムで活用できる
慣れてきたらmapやreduce、compactMapなどの便利メソッドも試してみるとより効率的にデータを扱える
Pythonのjoinで文字列結合|リストやタプルの要素をまとめて1つの文字列に
今回の記事でわかること
- Pythonで文字列を結合する方法
join()メソッドの基本的な使い方- リストやタプルの要素をまとめる方法
- 区切り文字を指定して結合する方法
- 応用例と注意点
join()とは
join() メソッドは、リストやタプルの要素を指定した文字列で結合して1つの文字列にするメソッドです
fruits = ["りんご", "バナナ", "みかん"]
result = ",".join(fruits)
print(result) # りんご,バナナ,みかん","が区切り文字join()の引数にリストやタプルを渡すと結合されます
空白や他の文字で結合
words = ["Python", "は", "便利"]
result = " ".join(words)
print(result) # Python は 便利
result = " - ".join(words)
print(result) # Python - は - 便利- 区切り文字は自由に設定可能です
- 見た目を整えるのにとても便利です
タプルでも使用可能
numbers = ("1", "2", "3")
result = "-".join(numbers)
print(result) # 1-2-3- タプルの文字列要素も結合できます
- 要素は文字列である必要があることに注意です
numbers = (1, 2, 3)
# result = "-".join(numbers) # エラーになる- 数値の場合は文字列に変換してから結合する必要があります
numbers = (1, 2, 3)
result = "-".join(str(n) for n in numbers)
print(result) # 1-2-3splitと組み合わせる
文字列を分割して加工して、再度結合することもできます
text = "りんご,バナナ,みかん"
fruits = text.split(",") # 分割
result = " & ".join(fruits) # 結合
print(result) # りんご & バナナ & みかん- データの整形や表示形式の変更に便利です
注意点
- joinの引数は文字列のイテラブル(リスト・タプルなど)である必要があります
- 数値や他の型がある場合は、文字列に変換する必要があります
- 区切り文字も文字列で指定する必要があります
まとめ
join()でリストやタプルの要素を1つの文字列にまとめられます- 区切り文字を自由に設定可能で、見た目を整えるのに便利です
- splitと組み合わせると、分割→加工→結合までの操作が簡単にできます
- 数値など文字列以外の要素は、文字列に変換してから結合する必要があります
文字列の分割(split)と結合(join)をマスターすると、Pythonでの文字列操作がほぼ自由自在になります
Pythonのsplitで文字列を分割する方法|区切り文字で簡単にデータを整理
この記事でわかること
- Pythonで文字列を分割する方法
split()メソッドの基本的な使い方- 区切り文字を指定した分割方法
- 複数区切りや最大分割数の指定
- 実用的な例と注意点
split()とは
split() メソッドは、文字列を指定した区切り文字で分割してリストにするメソッドです
text = "りんご,バナナ,みかん"
fruits = text.split(",")
print(fruits) # ['りんご', 'バナナ', 'みかん']- 文字列
"りんご,バナナ,みかん"をカンマで分割 - 結果はリストとして返されます
区切り文字を指定しない場合
区切り文字を指定しないと、空白(スペース)で分割されます
text = "Python は 便利"
words = text.split()
print(words) # ['Python', 'は', '便利']- 連続する空白も自動で1つとして扱われます
最大分割数を指定
maxsplit 引数で分割の最大回数を指定できます
text = "りんご,バナナ,みかん,メロン"
fruits = text.split(",", 2)
print(fruits) # ['りんご', 'バナナ', 'みかん,メロン']- 最初の2回だけ分割し、残りはそのまま1つの文字列になります
応用例:CSVデータの読み込み
line = "太郎,20,175"
name, age, height = line.split(",")
print(name) # 太郎
print(age) # 20
print(height) # 175- CSV形式の文字列からデータを取り出すのに便利です
- リストのアンパックと組み合わせるとさらに簡単に使えます
注意点
- 区切り文字が文字列に存在しない場合、結果は元の文字列1つのリストになります
- 複数の区切り文字が混ざっている場合は、正規表現の
re.split()が必要です - 結果は常にリストになるので、扱いやすい形に変換することを意識すると良いです
まとめ
split()で文字列を指定した区切りで分割してリスト化できます- 区切り文字を省略すると空白で分割されます
maxsplitで分割回数を制限できます- CSVやスペース区切りのデータ処理に非常に便利です
文字列を分割する方法を覚えると、データ処理や文字列操作の幅が大きく広がります
Pythonの文字列フォーマット|f文字列・format・%演算子で出力を整える方法
この記事でわかること
- Pythonで文字列をきれいに整形する方法
- f文字列(f-strings)の使い方
format()メソッドで変数を埋め込む方法- 旧式の
%演算子によるフォーマット - 数値や文字列の整形、桁揃えや小数点指定の方法
f文字列(f-strings)
Python 3.6以降で使える一番便利な方法です
name = "太郎"
age = 20
print(f"名前は{name}、年齢は{age}歳です")出力:
名前は太郎、年齢は20歳です- 文字列の前に
fをつける {}の中に変数や計算式を書ける
width = 10
height = 5
print(f"面積は{width * height}です") # 面積は50です計算結果も直接埋め込めます
format() メソッド
古い方法ですが、Python 3でも使えます
name = "太郎"
age = 20
print("名前は{}、年齢は{}歳です".format(name, age)){}の順番に.format()の引数を入れます
番号を付けて順番を入れ替えることもできます
print("年齢は{1}歳、名前は{0}".format(name, age))%演算子によるフォーマット(旧式)
C言語風の書き方です
name = "太郎"
age = 20
print("名前は%s、年齢は%d歳です" % (name, age))%sは文字列、%dは整数- 古い書き方ですが、まだ一部で使われています
数値の整形
f文字列を使うと、桁揃えや小数点の指定も簡単です
pi = 3.141592
# 小数点以下2桁まで
print(f"円周率は{pi:.2f}") # 円周率は3.14
# 幅を指定して右寄せ
print(f"{pi:10.2f}") # 3.14(10文字幅):.2fで小数点以下2桁10.2fで幅10文字・小数点2桁
文字列の整形例
name = "太郎"
score = 95
# 左寄せ
print(f"{name:<10} {score}") # 太郎 95
# 右寄せ
print(f"{name:>10} {score}") # 太郎 95表形式で並べたいときに便利です
まとめ
- f文字列はPython 3.6以降の便利で直感的な方法です
format()メソッドも柔軟に使えます%演算子は旧式ですが覚えておくと互換性で便利です- 数値や文字列の整形、桁揃え、小数点指定も可能です
- データを見やすく表示したいときに欠かせないテクニックです
文字列フォーマットをマスターすると、出力の見た目もきれいに整えられて、プログラムの完成度がぐっと上がります
PythonでLINQ風操作をやさしく解説|リスト内包表記・map・filterでデータ処理を効率化
この記事でわかること
- PythonでLINQ的な操作とは何か
- リスト内包表記・map・filterを組み合わせた便利なデータ操作
- 条件付きの抽出・変換・集計の方法
- 複雑なリスト処理を効率的に書く考え方
C#のLINQのように、データを「絞る・変換する・集計する」操作を簡単に書く方法をPythonで理解できます
LINQ風操作とは
LINQは、C#でリストや配列を操作するときに使う便利な仕組みです
Pythonでは、リスト内包表記、map、filter、sumなどを組み合わせることで同じような操作ができます
例:条件で絞りつつ変換する
numbers = [1, 2, 3, 4, 5]
# 偶数だけを2倍にする
result = [x * 2 for x in numbers if x % 2 == 0]
print(result) # [4, 8]これだけで LINQでいうWhere + Select の操作ができます
mapとfilterで書く場合
同じ処理をmapとfilterで書くこともできます
numbers = [1, 2, 3, 4, 5]
# filterで偶数だけ抽出して、mapで2倍に変換
result = list(map(lambda x: x * 2, filter(lambda x: x % 2 == 0, numbers)))
print(result) # [4, 8]- filterで条件を満たすものだけ取り出す
- mapで取り出した要素を変換
この流れはLINQの Where と Select に対応しています
集計も簡単
Pythonでは sum や len を組み合わせることで、集計もできます
numbers = [1, 2, 3, 4, 5]
# 偶数の合計
total = sum(x for x in numbers if x % 2 == 0)
print(total) # 6LINQでいう Sum や Count のような操作です
複数条件や組み合わせも可能
リスト内包表記で複雑な条件や組み合わせも簡単に書けます
numbers = [1, 2, 3]
letters = ["a", "b"]
# 全ての組み合わせ
result = [(n, l) for n in numbers for l in letters]
print(result) # [(1, 'a'), (1, 'b'), (2, 'a'), ...]LINQの SelectMany に相当する操作も直感的に書けます
注意点
- 内包表記やmap/filterで無理に1行にすると読みにくくなる
- 集合演算や複雑なネストが多い場合は、for文で分けて書く方が安全
- 慣れると、SQLライクにデータを操作できるようになり、コードがすっきりします
まとめ
- PythonでのLINQ的操作は、リスト内包表記・map・filter・sumなどで実現できます
- 条件で絞る(Where)、変換する(Select)、集計する(Sum/Count)を組み合わせると効率的です
- 複数リストの組み合わせや複雑な条件も直感的に書けます
- コードを簡潔に書ける反面、読みやすさを意識することが大事です
これで、Pythonでのデータ操作の基礎から応用まで、ほぼ一通り揃いました
- 入出力・変数・型
- 式・演算子
- 条件分岐
- 繰り返し処理
- List / Set / Dictionary / Tuple
- リスト内包表記・map/filter
- LINQ風操作
この流れを理解すれば、初心者でも データを自由自在に扱うプログラム が書けるようになります